

Chciałbyś zostać kotem internetu lecz nie wiesz jak się za to zabrać? W tej serii artykułów postaram Ci się przedstawić przykładową ścieżkę nauki. Obranie dobrej strategii uczenia się bardzo ją ułatwi naukę i obniży próg wejścia do świata IT, ponieważ Twoja wiedza będzie się zwiększać przyrostowo zaczynając od najbardziej podstawowych rzeczy. Sama nauka nie wystarczy, dlatego w proponowanej ścieżce kariery będę zaznaczał jak ważna jest praca własna włożona w naukę i własne projekty, przy których wykorzystasz wiedzę w praktyce.
Zapraszam do zapoznania się z artykułami z cyklu Chce zostać kotem internetu!
Od czego zacząć naukę?
Na początku Twojej nauki polecałbym zapoznać się z tym z czego, w dużym skrócie, składają się nowoczesne aplikacje/portale internetowe. Pozwoli Ci to zdecydować jaka rola byłaby dla Ciebie odpowiednia. Tworzenie nowoczesnych portali internetowych wymaga wielu kompetencji, dlatego też wybór odpowiedniej dla siebie ścieżki jest bardzo ważny i pozwoli Ci uniknąć zbędnych frustracji.
Z czego składają się nowoczesne portale internetowe?
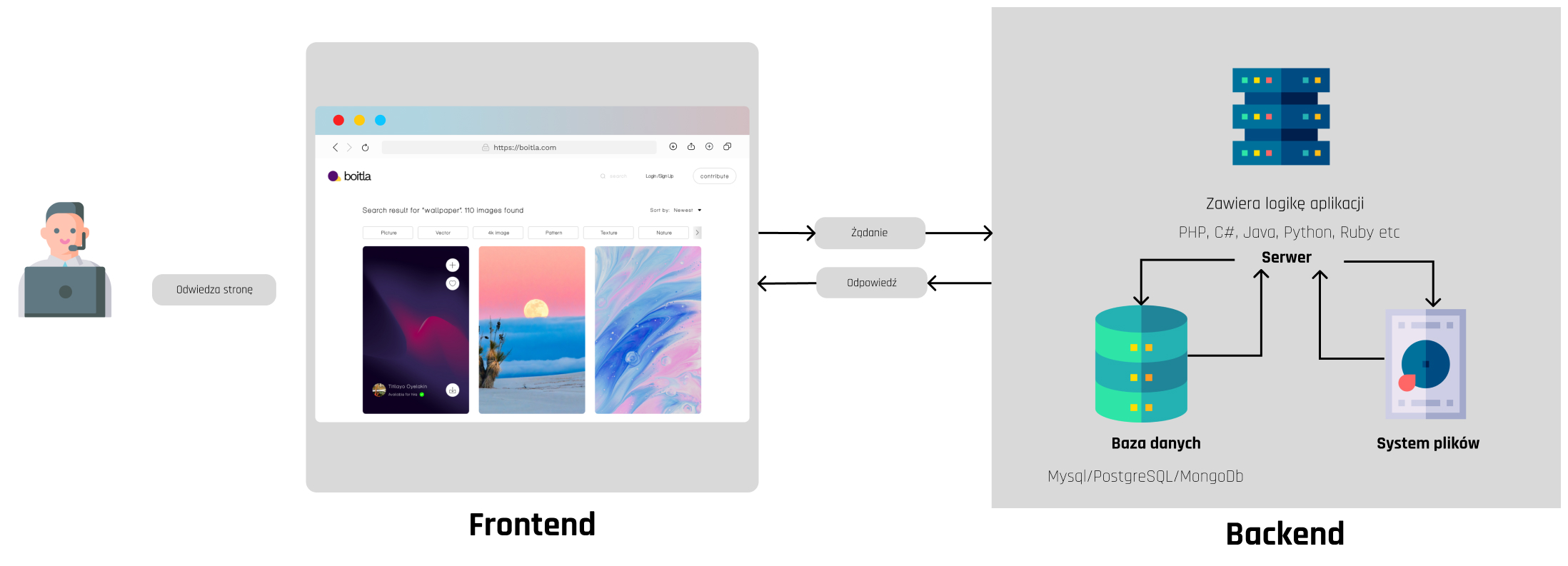
Portale internetowe składają się z dwóch głównych elementów, takich jak Frontend oraz Backend. Frontend jest to widoczna dla użytkownika część portalu internetowego. Dostarcza mechanizmy pozwalające na wchodzenie użytkownika w interakcję z portalem. Backend natomiast zajmuje się wszystkim tym, czego użytkownik nie widzi. Odpowiada za przetwarzanie oraz zapis danych wprowadzanych przez użytkowników. Jest on odpowiedzialny także za dostarczanie danych do wyświetlenia na stronie. Więcej na temat tego czym jest frontend możesz przeczytać na strone SDA Academy – Co to jest Front-end i kim jest frontend developer? Jeśli natomiast zainteresował Ciebie temat backendu i chcesz dowiedzieć się czegoś więcej na ten temat to polecam sprawdzić artykuł: Co to jest Back-end i kim jest backend developer?
Wybrałem swoją internetową specjalizacje – zacznijmy naukę!
Na początku Twojej drogi związanej z nauką programowania portali internetowych, polecałbym poznać podstawowe mechanizmy działania internetu. Tak, tak nauki programowania nie zaczynamy od nauki języka, tylko od poznania teorii. Najpierw musisz poznać mechanizmy, których będziesz używał w codziennej pracy a dopiero później możesz zająć się programowaniem.
Jak działa internet?
Na początek Twojej przygody z nauką programowania portali internetowych polecam Ci zapoznać się dokładniej z tym jak działa internet. Dobre poznanie zasad działania internetu ułatwi Ci naukę w jej dalszych etapach oraz wpłynie na to, że będziesz świadomy mechanizmów, z których korzystasz. Dzięki temu unikniesz zbędnych frustracji oraz szybciej będziesz się rozwijał.
Czym w ogóle jest internet?
Z kolei w definicji informatycznej, internet to przestrzeń adresów IP przydzielonych hostom i serwerom połączonym za pomocą urządzeń sieciowych, takich jak karty sieciowe, modemy i koncentratory, komunikujących się za pomocą protokołu internetowego z wykorzystaniem infrastruktury telekomunikacyjnej (źródło: Wikipedia).
Do identyfikacji urządzeń w internecie wykorzystywane są adresy IP. Każde urządzenie, które zostało podłączone do internetu posiada przypisany adres, który pozwala na jego identyfikację w sieci oraz jest wykorzystywany do komunikacji z innymi urządzeniami.
Czym jest adres IP?
Ze względu na to, że każde urządzenie dostępne w sieci musi mieć przypisany swój własny unikalny adres powstały różne strategie jego przypisywania:
- statyczne – jest to adres, który się nie zmienia i jest na stałe przypisany do urządzenia
- dynamiczne – adres IP jest zmienny i jest przyznawany każdorazowo przy podłączeniu do sieci lub po upływie określonego czasu
Większość użytkowników aktualnego internetu korzysta z dynamicznego przypisywania adresu IP. Dynamiczne adresy są przypisywane dzięki wykorzystaniu serwera DHCP, który odpowiada za przypisanie każdemu użytkownikowi sieci unikalnego adresu IP, pozwala to na łączenie się się z internetem z wielu miejsc bez martwienie się o konflikt adresów i bez konieczności ręcznego jego ustawiania dla każdej sieci, do której się podłączysz.
Statyczna adresacja jest bardzo ważna w świecie internetu, ponieważ to dzięki niej funkcjonują np. domeny. Za pomocą statycznych adresów IP po wpisaniu w okno przeglądarki google.pl pojawi Ci się strona wyszukiwarki.
Aktualnie w użyciu są 2 rodzaje adresów ip:
- IPv4 – zostało wynalezione w latach 80 oraz składa się 4 liczb z zakresu 0-255 np. 127.0.0.1. Jest używany jako główny protokół adresacji w sieci.
- IPv6 – zostało wynalezione w latach 90 jako nowsza wersja IPv4 i składa się z 8 16-bitowych liczb.
Zastanawiałeś się kiedyś jak to się dzieje, że po wpisaniu nazwy strony przeglądarka wie jaką stronę chcemy wyświetlić i jaką maszynę ma zapytać o te informacje? Dzieje się to dzięki wykorzystaniu usług DNS (Domain Name System), które pozwalają na translację domeny na konkretny adres IP.
Co to DNS?
DNS czyli Domain Name System jest hierarchiczny rozproszony system nazw domen. Ale co to znaczy? DNS jest odpowiedzialny za translację nazwy domeny (łatwej dla zrozumienia i zapamiętania przez człowieka) na adres maszyny w sieci, np. po wpisaniu w przeglądarkę devkot.pl DNS przetłumaczy tą nazwę na: 46.242.232.142 co odpowiada adresowi IP maszyny na której postawiona jest ta strona. Ale jak to się dzieje?
- Wpisujesz w przeglądarce devkot.pl
- Przeglądarka wysyła zapytanie do znanego jej serwera DNS z prośbą o wysłanie jej adresu IP dla domeny devkot.pl
- Serwer DNS odpowiada na żądanie i jako odpowiedź przesyła adres IP przypisany do danej domeny
- Przeglądarka łączy się z podanym adresem IP i wyświetla stronę
Skąd DNS wie jakie jest adres IP dla domeny internetowej?
Rekord A
| Typ | Nazwa domeny | TTL | Wartość | ||||
|---|---|---|---|---|---|---|---|
| A | devkot.pl | 3600 |
46.242.232.142
|
||||
Rekord CNAME
| Typ | Nazwa Domeny | TTL | Wartość | ||||
|---|---|---|---|---|---|---|---|
| CNAME | *.devkot.pl | 3600 | devkot.pl | ||||
W powyższym przykładzie widać, że wszystkie subdomeny, które powstaną w domenie devkot.pl np test.devkot.pl będą korzystać z tych samych rekordów DNS co devkot.pl, czyli DNS zwróci ten sam adres IP.
Rekord MX
Rekordy MX są odpowiedzialne za wskazanie położenia serwera obsługującego pocztę email. Rekordom MX można nadawać priorytet. Wiadomości poczty elektronicznej przekazywane są do serwera z najwyższym priorytetem i jeśli z jakiegoś powodu on nie da rady obsłużyć danej wiadomości to przekazywane są do kolejnych zgodnie ze zmniejszającym się priorytetem.
Przykład
| Typ | Nazwa Domeny | TTL | Priorytet | Wartość | ||||
|---|---|---|---|---|---|---|---|---|
| MX | devkot.pl | 3600 | 10 | devkot.pl | ||||
Rekord NS
Istnieją jeszcze wiele innych rekordów dns, więcej na ten temat możesz przeczytać tutaj: DNS co to jest i jak działa? oraz tutaj Jak działa system DNS?
Jak transportowane są informacje w internecie?
Za transport informacji w internecie odpowiada tzw. warstwa transportowa. Zapewnia ona usługi przesyłania danych z hosta źródłowego do hosta docelowego. Nawiązuje połączenie między urządzeniem wysyłającym oraz odbierającym, które pozwala na transport danych. Warstwa transportowa odpowiada także za segmentacje i scalanie danych, które są wysyłane strumieniem między punktami końcowymi. Do przenoszenia danych między dwoma urządzeniami końcowymi służą dwa podstawowe protokoły warstwy transportowej, a mianowicie: TCP i UDP.
TCP
Schemat segmentu TCP:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Zawartość pól segmentu:
- Port źródłowy – port aplikacji, z której wysłano dane
- Port docelowy – port aplikacji, do której wysłano dane
- Numer sekwencyjny – numer ostatniego bajtu w segmencie (wykorzystywany jest w procesie scalania danych do weryfikacji czy dane zostały przesłane prawidłowo)
- Numer potwierdzający – numer następnego bajtu w segmencie (wykorzystywany jest w procesie scalania danych do weryfikacji czy dane zostały przesłane prawidłowo)
- Długość – długość całego segmentu TCP
- Znaczniki – sześć bitów służących do oznaczania specjalnych funkcji pakietu
URG – oznacza, że pakiet zawiera tzw. pilne dane
ACK – potwierdzenie
PSH – funkcja PUSH
RST – oznacza natychmiastowe zerwanie połączenia
SYN – używany przy nawiązywaniu połączenia, oznaczający synchronizację numerów sekwencyjnych nadawcy i odbiorcy
FIN – zakończenie połączenia - Rozmiar okna – ilość danych jaka może zostać przesłana bez potwierdzenia
- Suma kontrolna – używana do sprawdzenia poprawności przesłanych danych
- Wskaźnik ważności – używany tylko kiedy ustawiona jest flaga URG
Nawiązywanie połączenia TCP:
- Maszyna 1 wysyła do maszyny 2 segment SYN
- Maszyna 2 po otrzymaniu komunikatu SYN odpowiada maszynie 1 segmentem SYN a następnie segmentem ACK
- Maszyna 1 po odebraniu segmentów SYN i ACK wysyła maszyny 2 segment ACK i w tym momencie połączenie między tymi dwoma maszynami zostało ustanowione.
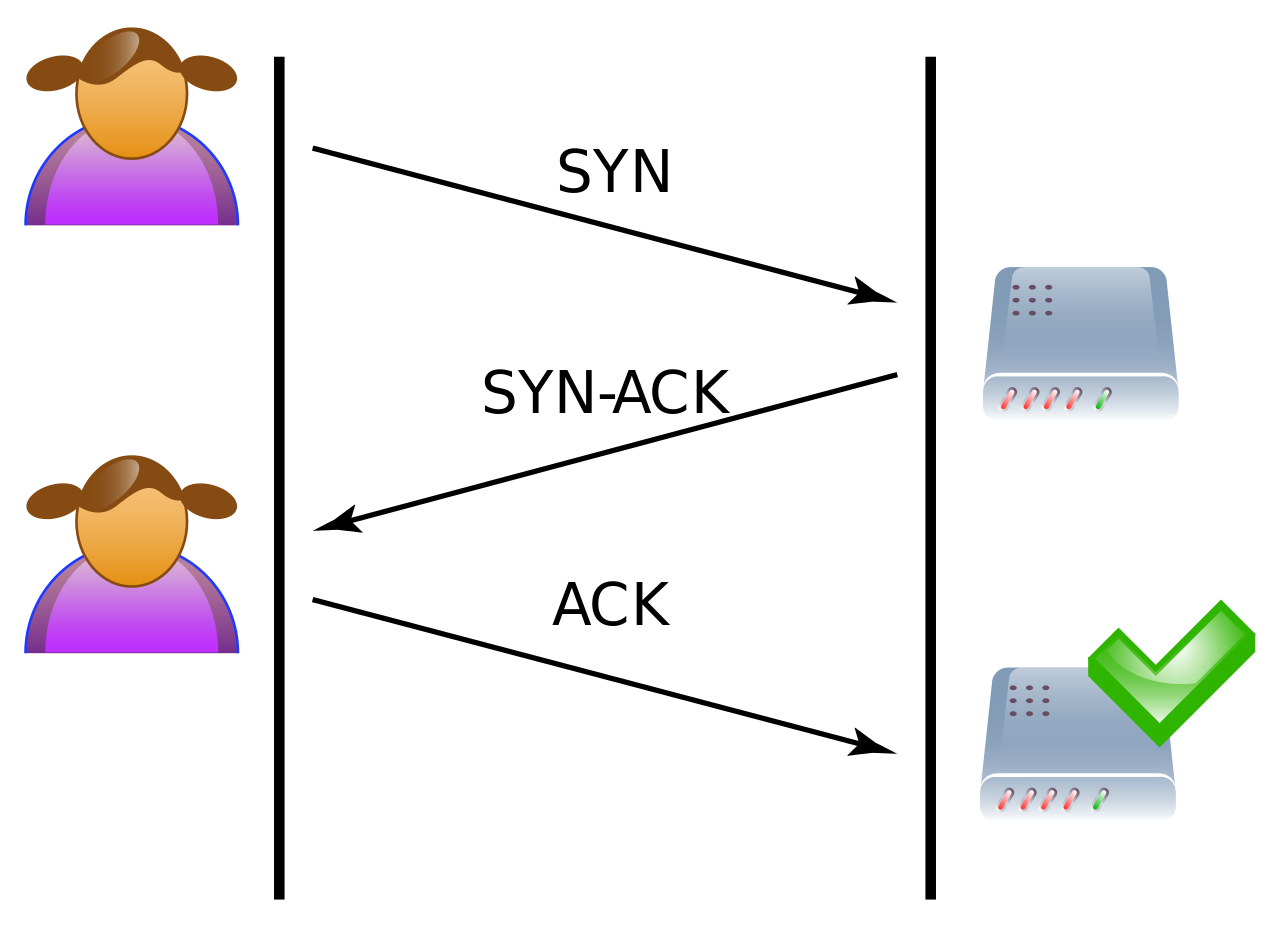
W celu weryfikacji wysyłki i odbioru TCP używa sum kontrolnych i sekwencyjnych numerów pakietów. Odbiorca potwierdza otrzymanie pakietów o określonych numerach sekwencyjnych ustawiając flagę ACK. W przypadku gdy jakiegoś pakietu brakuje jest on wysyłany ponownie. Maszyna odbierająca scala segmenty TCP i przyporządkowuje je według numerów sekwencyjnych.
Więcej na temat TCP możesz przeczytać tutaj:
UDP
Innym protokołem odpowiedzialnym za transport danych między urządzeniami w sieci jest UDP (User Datagram Protocol). Jest on dużo prostszy od TCP ze względu na to, że nie posiada on mechanizmów gwarantujących niezawodność oraz spójność danych jak i nie posiada mechanizmów pozwalających na kontrolę przepływu.
Schemat segmentu UDP:
| + | Bity 0 – 15 | 16 – 31 | ||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Port nadawcy | Port odbiorcy | ||||||||||||||||||||||||||||||
| 32 | Długość | Suma kontrolna | ||||||||||||||||||||||||||||||
| 64 | Dane | |||||||||||||||||||||||||||||||
Zawartość pól segmentu UDP:
- Port nadawcy- port aplikacji, z której wysłano dane
- Port odbiorcy – port aplikacji, do której wysłano dane
- Długość – długość całego segmentu UDP
- Suma kontrolna – używana do sprawdzenia poprawności przesłanych danych


2 Responses
kiedy część druga? 🙂
Cześć, druga część na początku kolejnego tygodnia 🙂 Prawdopodbnie poniedziałek/wtorek.